

如何在OCR中提取特定语言文字?
发布时间:20231025 来源:极光PDF 作者:牛叔

随着数字化时代的到来,我们对文档的处理和管理需求越来越高。光学字符识别(OCR)技术为我们提供了一种有效的方法,将印刷或手写文字从纸张或图像中提取到数字文本中。然而,在不同语言环境下,如何精确提取特定语言文字成为了一个具有挑战性的问题。本文将探讨如何在OCR中提取特定语言文字,并提供一些建议和技巧,以确保准确性和可靠性。
一、选择适当的OCR工具
市面上有许多OCR软件和服务可供选择,其中一些可以处理多种语言。在选择OCR工具时,确保它支持您所需的特定语言。一些OCR工具可能专门设计用于特定语言,因此可以提供更好的性能。
二、准备清晰的源文件
为了获得最佳的OCR结果,确保您的源文件是清晰的,没有模糊或扭曲的文字。使用高分辨率扫描或照片,以便OCR工具能够更容易地识别文字。此外,确保文档没有水印或其他干扰因素,这些因素可能会降低OCR的准确性。

三、调整OCR设置
不同语言的文字具有不同的特征,因此在使用OCR时需要调整设置以适应特定语言。一些OCR工具允许您选择目标语言,这将有助于提高准确性。此外,您还可以调整识别引擎的设置,如文本方向、字体类型和字号,以更好地匹配目标语言的特点。
四、使用专用字典和模型
一些OCR工具允许您使用特定语言的字典和模型,以提高识别准确性。这些字典包含特定语言的词汇和语法规则,可以帮助OCR工具更好地理解文本。使用专用字典和模型可以显著提高特定语言文字的提取效果。
五、校正OCR结果
尽管OCR技术已经相当成熟,但它仍然可能出现错误。一些OCR工具提供文本校正功能,允许您手动编辑或校正识别错误。在处理特定语言时,检查和校正文本尤为重要,以确保准确性。
六、使用上下文信息
在提取特定语言文字时,考虑上下文信息可以提供更多的线索。特定语言通常遵循特定的语法和结构规则,因此了解这些规则可以帮助您更好地识别文本。此外,使用上下文信息可以帮助您纠正OCR可能出现的歧义。
七、使用OCR API
一些云服务提供OCR API,可以轻松地将OCR功能集成到您的应用程序或工作流程中。这些API通常具有多语言支持,并且可以根据您的需求进行自定义配置。使用OCR API可以提供更大的灵活性和自动化。
在提取特定语言文字时,可能会面临一些挑战。不同语言具有不同的字母、字符和字体,这可能会导致OCR的识别难度增加。此外,手写文字和低分辨率图像也可能导致识别问题。因此,在处理特定语言时,需要特别小心。而为了更好地处理提取的特定语言文字,推荐使用专业的PDF编辑软件,如极光PDF编辑器。这是一款强大的PDF编辑工具,它不仅支持多种语言的文字提取,还提供了丰富的编辑功能,以便更好地处理文档。

极光PDF编辑器的主要特点包括:
● 多语言支持:极光PDF编辑器支持多种语言的文字提取,包括常见的欧洲语言、亚洲语言和中东语言。
● OCR功能:该编辑器内置OCR功能,可以将图像或扫描的文档转换为可编辑的文本,并支持特定语言的识别。
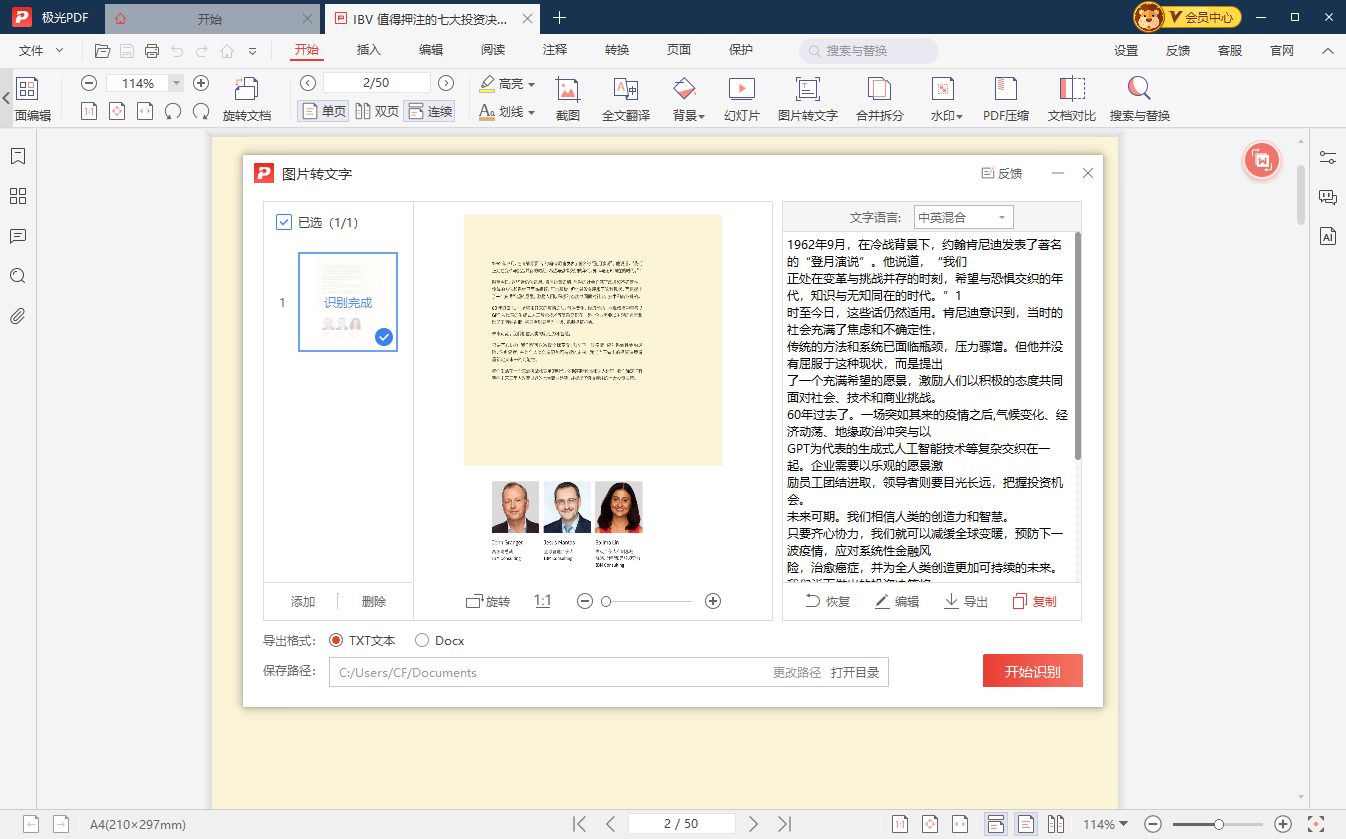
● 文本编辑工具:您可以使用该编辑器的文本编辑工具来轻松编辑和格式化提取的文本,以满足您的需求。
● 批注和注释:极光PDF编辑器还提供了批注和注释功能,以便您在文档中添加注释、标记和签名。
● 安全性:您可以使用加密和密码保护功能来确保文档的安全性,特别是对于包含敏感信息的文档。
综上所述,如何在OCR中提取特定语言文字是一个重要的问题,涉及到文档处理和管理的各个领域。选择适当的OCR工具,校正OCR结果,使用上下文信息以及推荐使用专业的PDF编辑软件,如极光PDF编辑器,都可以帮助您更好地处理特定语言的文字提取任务。随着技术的不断发展,我们可以期待OCR技术在提取特定语言文字方面取得更大的突破。

更多动态请关注微信公众号,请使用微信“扫一扫”

